تشخیص شیء در تصویر یکی از مسائل بینایی کامپیوتر است. منظور از تشخیص، تمیز دادن اشیاء از یکدیگر و صدالبته تعیین نوع شیء (درخت، اتومبیل، گربه، هواپیما و ..) و منظور از شیء هر چیز قابل جدا کردن از صحنه بهعنوان یک موجودیت مستقل است (شامل اجسام مرده و موجودات زنده).
روشهای متعددی برای تشخیص اشیاء ابداع شده است؛ در همه این روشها ویژگیهای (feature) تصویر استخراج و سپس از روی ویژگیها با استفاده از الگوریتمهای یادگیری ماشین تصاویر تشخیص داده میشود. از جنبهی استخراج ویژگی (feature extraction) از تصویر میتوان الگوریتمهای تشخیص شیء را به دو دسته کلی با و بدون یادگیری عمیق تقسیم کرد.
سابق بر این ویژگیها بهصورت دستی استخراج و بهعنوان ورودی تکنیکهایی نظیر SVM از آنها استفاده میشد. در حال حاضر با توسعه یادگیری عمیق فرایند استخراج ویژگی نیز به شبکه عصبی واگذارشده و کل فرایند استخراج ویژگی و دستهبندی اشیاء یکجا به شبکه آموزش داده میشود.
بهترین تشخیصدهندهها از نوع «تشخیصدهنده کاملاً نظارتشده» (FSD) ارائهشدهاند. ایراد اصلی این تشخیصدهندهها نیازشان به یک مجموعه داده نسبتاً بزرگ علامتگذاری شده (Annotated) است.
در تشخیص شیء علامتگذاری به مستطیلهایی که دور اشیاء کشیده شده و برچسبهایی که به آنها تخصیص دادهشده است، گفته میشود. برای این نوع شبکهها قبل از آموزش شبکه که کار زمانبری است و بهصورت خودکار انجام میشود، زمانبرترین کار آمادهسازی مجموعه داده است، که غالباً بهصورت دستی آماده میشود.
برای رفع این مسئله رهیافت «تشخیصدهنده بهطور ضعیف نظارتشده» (WSD) ارائهشده است. از طرف دیگر برخی دیگر از پژوهشها از با تنظیم شبکه آموزشدیده در یک حوزه در خوزه دیگری استفاده میکنند. همانطور که از عنوان مقاله پیداست این پژوهش نیز در این دو دسته طبقهبندی میشود.
مشخصات مقاله
نوع: کنفرانس (CVPR2018)
نویسندگان: Naoto Inoue ; Ryosuke Furuta ; Toshihiko Yamasaki ; Kiyoharu Aizawa
لینک دانلود مقاله: اینجا
کد مقاله: اینجا
مسئله
ما یک شبکه که با تصاویر طبیعی علامتگذاری شده آموزشدیده است، در اختیارداریم. این شبکه توانایی تشخیص اشیاء معمولی را دارد. آیا میتوان بدون ساخت مجموعه داده (جدید) علامتگذاری شده (بهصورت دستی) شبکه را طوری آموزش داد تا همان اشیاء را در حوزههای دیگر (نقاشی، Clip Art و …) تشخیص دهد؟
نوآوری
ایده کلی این مقاله در شکل زیر آمده است. در مرحله اول یک شبکه آموزشدیده با مجموعه داده علامتگذاری شده (مثلاً COCO) در اختیار داریم.
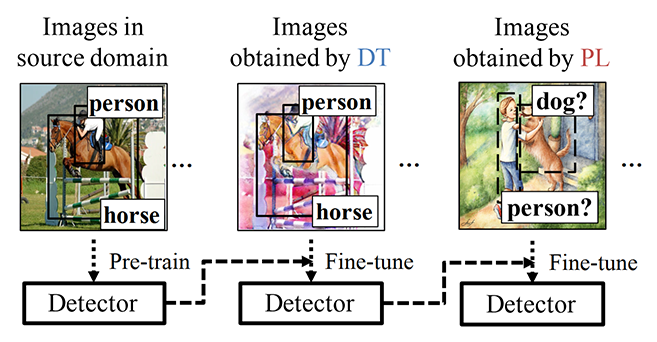
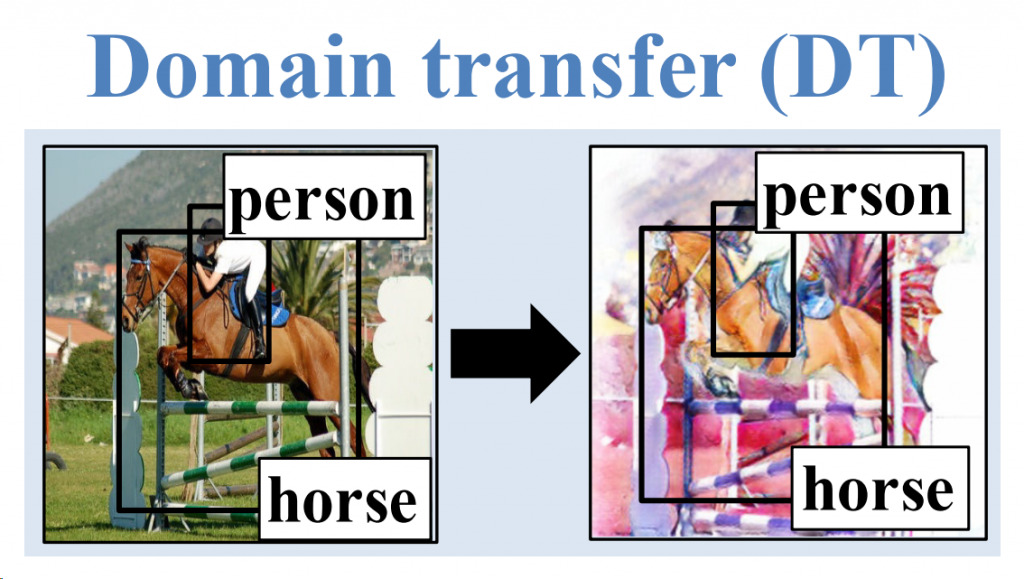
در مرحله بعد با کمک شبکه CycleGAN اقدام به انتقال حوزه تصویر (ترجمه تصویر به تصویر، مثلاً تصویر طبیعی به نقاشی آبرنگ) میکنیم. ما یک مجموعه داده علامتگذاری شده از تصاویر طبیعی را در اختیار داریم (مثلاً COCO). با استفاده از شبکه CycleGAN تمامی این تصاویر را تبدیل به نقاشی آبرنگ میکنیم. علامتگذاریها هم که سرجایش باقی میماند. حال مجموعه داده علامتگذاری شدهای از تصاویر نقاشی آبرنگ خواهیم داشت. با همین مجموعه شبکه را آموزش تنظیم میکنیم.
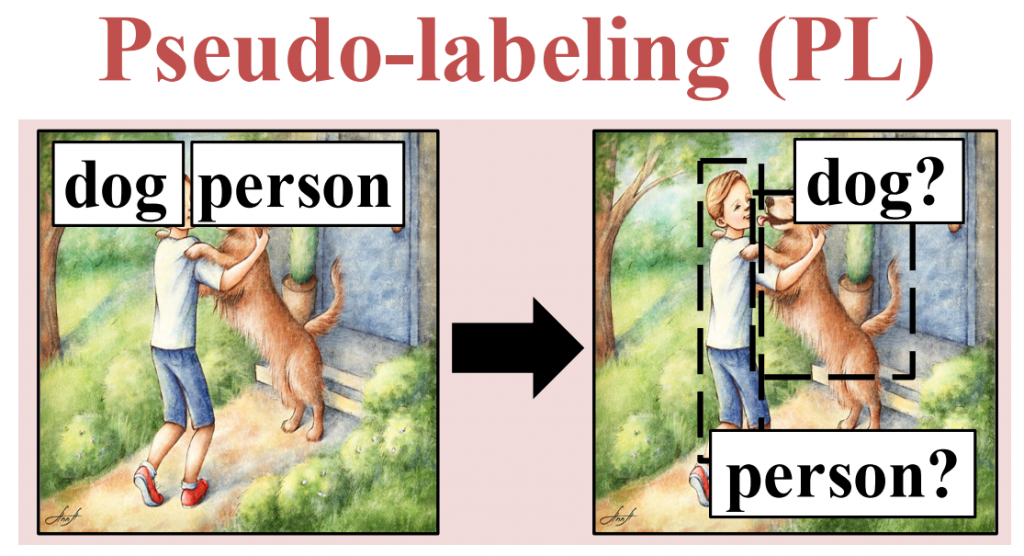
گام بعدی تنظیم شبکه شبه برچسب زنی نامیده می شود. در این فرایند ابتدا خروجی FSD بدست می آید. خروجی FSD اشیاء را با احتمالی تشخیص می دهد. محتملترین تشخیص ها در هر کلاس جدا شده و در مجموعه شبه برچسب نگهداری می شود. از این مجموعه برای تنظیم شبکه در این مرحله استفاده می شود.
در آزمایشات این پژوهش از شبکه SSD300 به عنوان شبکه پایه استفاده شده و از مراحل فوق به صورتی تکی و با هم برای تنظیم شبکه استفاده شده است.
تحلیل
در بخش انتقال حوزه تصویر کار سخته رو CycleGen انجام داده و یکی از ایده های خوب این مقاله استفاده از چنین شبکه ای برای تولید خودکار یک دیتاست از روی دیتاست دیگه است.
کد مقاله رو ما برای تشخیص یک شیء جدید استفاده کردیم. یعنی یک دیتاست جدید آماده کردیم و به خورد شبکه دادیم. ایراد استفاده از شبکه پایه و تنظیم اون برای حوزه های جدید که ما هم تو کارمون بهش برخوردیم اینه که نمیشه کلاس جدیدی به مجموعه کلاس اشیاءای که شبکه پایه میتونه تشخیص بده اضافه کرد. مجبور شدیم از همون کلاس های موجود برای این کار استفاده کنیم!
کدش به نسبت بقیه خوش دست تر هست و راحت اجرا میشه! اصلا یکی از دلایل انتخاب من برای بررسی مقاله به عنوان اولین مقاله در حوزه تشخیص اشیاء با کمک یاگیری عمیق، همین بود!
پینوشت
برای این که بتونیم شبکه رو سریع آموزش بدیم با دوستان یه سیستم نسبتا خوب برای پروژه های Deep Learning آماده کردیم.


اینم کانفیگ سیستم:
GPU: NVIDIA GeForce GTX 1080 Ti
RAM: 2 X 16GB DDR4 TForce Nighthawk Dual Channel
CPU: Intel Core i7 – 8700
Main Board: ASUS TUF Z370-PLUS GAMING! ?
SSD: 256 GB
HDD: 2 TB
Power: 1200 Watt
GPU در یادگیری و تست شبکه عصبی بیش از صد برابر سریعتر از CPU است. هزینه عمده جمع آوری سیستم صرف GPU میشه. در مورد GPU عرض کنم خدمت شما که یه بررسی تو بازار و کارت گرافیک های NVIDIA که از CUDA پشتیبانی می کنند، انجام دادیم. از نظر پردازشی 1080Ti وضعیت بهتری نسبت به TITAN X داره.

برای پروژه های یادگیری عمیق یه مقدار TitanX بهتر از 1080Ti هست ولی از نظر کارایی به قیمت 1080Ti وضعیت بهتری داره. البته 2080Ti هم وضعیت بهتری از 1080Ti دارد (حدود ۳۵ درصد) ولی قیمتش تقریبا دو برابر 1080Ti هست. این هم کارایی که میده نسبت به قیمت نمی صرفه. نمودار زیر مقایسه ای بین پردازنده ها (به ویژه در حالتی که از چند GPU همزمان استفاده شود، ما که زورمون به یه دونه رسید) در این نمودار معیار Titan V است.
وقتی که شبکه رو Train می کنید می تونید میزان مصرف GPU رو در Task Manager ببینید. (ما از ویندوز استفاده می کنیم!) فقط باید در بخش GPU گزینه Cuda رو انتخاب کنید تا کارایی پردازنده گرافیکی رو در زمان آموزش و تست شبکه ببینید.
بررسی دیگران
بررسی دیگری برای این مقاله تا به امروز یافت نکرده ام.
مطالب مرتبط
بررسی مقاله: Chitty-Chitty-Chat Bot: Deep Learning for Conversational AI
بررسی مقاله: Learning by Asking Questions
مراجع مهم
1. H. Bilen and A. Vedaldi. Weakly supervised deep detection networks. In CVPR, 2016
2. X. Chen and A. Gupta. Webly supervised learning of convolutional networks. In ICCV, 2015
3. R. Girshick. Fast R-CNN. In ICCV, 2015
4. S. Ren, K. He, R. Girshick, and J. Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS, 2015
5. S. Tokui, K. Oono, S. Hido, and J. Clayton. Chainer: a nextgeneration open source framework for deep learning. In NIPS workshop, 2016
6. M. J. Wilber, C. Fang, H. Jin, A. Hertzmann, J. Collomosse, and S. Belongie. BAM! the
دیدگاهتان را بنویسید