بهترین واسط تعاملی میان انسان ها مکالمه است. اول که به هم میرسیم با گفتن سلام شروع می کنیم به مکالمه؛ خوب اگر واسط میان انسان و ماشین (بجای موس و کیبورد و …) به مکالمه گفتاری تبدیل بشه حس بهتری از برقرار ارتباط با ماشین پیدا می کنیم.
مشخصات مقاله
نوع: کنفرانس (IJCAI 18) نویسنده: Rui Yan
لینک دانلود مقاله: اینجا
مسئله
هوش مصنوعی مکالمه (Conversational AI)
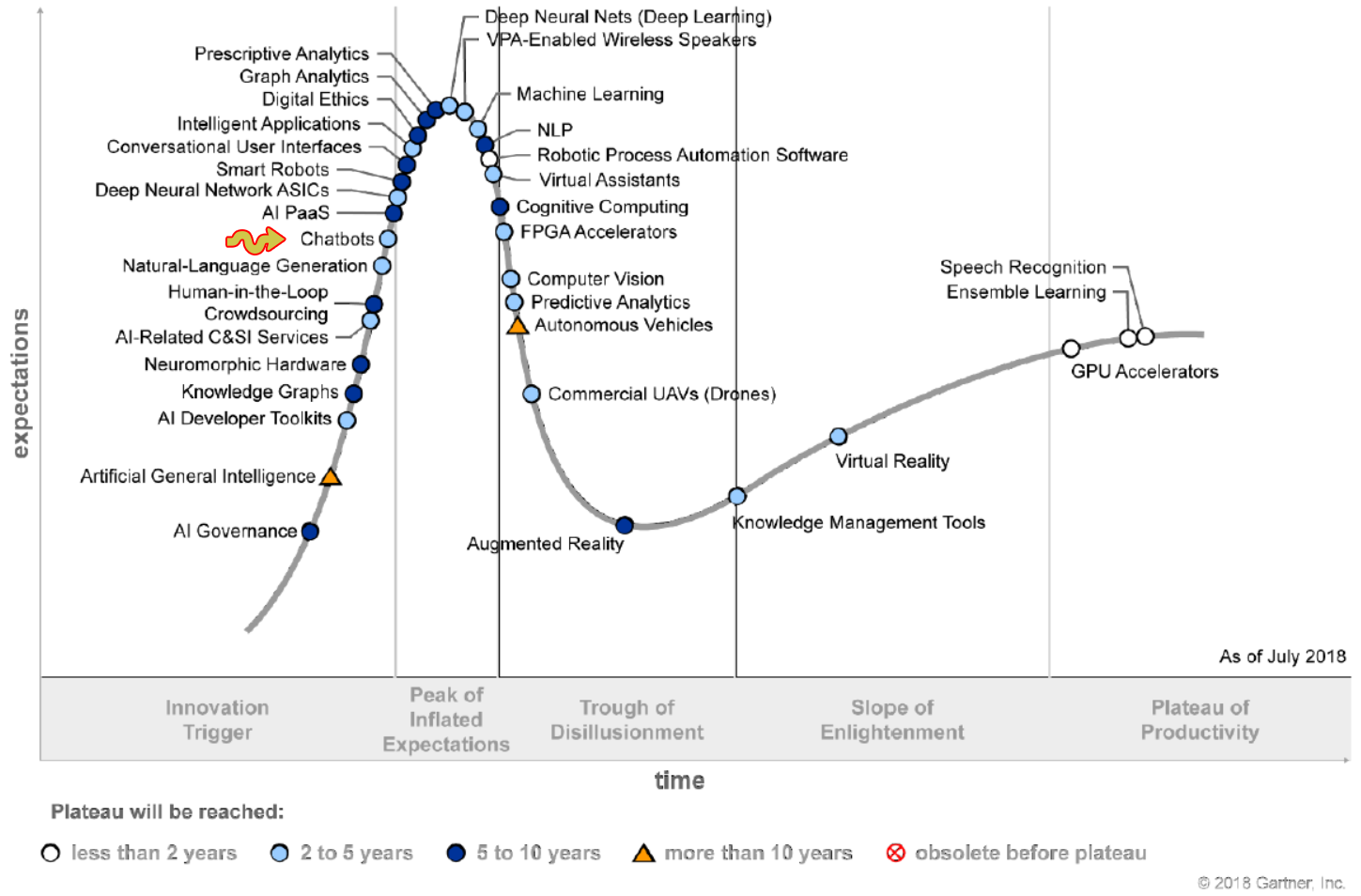
یک حوزه پژوهشی در حال رشد و مهم است. از کجا فهمیدیم که مهمه؟! جدا از
بررسی تعداد مقالات منتشر شده در این زمینه در چند سال اخیر، کافیه یه نگاه
به نمودار چرخه hype گارتنر بندازید و موقعیت هوش مصنوعی مکالمه (تحت عنوان Chatbots) رو در این
نمودار پیدا کنید. (در شکل زیر با فلش مشخص شده) هوش مصنوعی مکالمه در دو
زمینه دستیار مجازی و ربات اجتماعی پتانسیل های تجاری زیادی دارد. برای
مثال می توان به Little Bing (یا همان XiaoIce)
شرکت مایکروسافت برای کاربران چینی، به عنوان نمونه ای از ربات عمومی (یک
محصول صنعتی و نه فقط آکادمیک) اشاره کرد. این بات مکالمه در سال 2014 راه
اندازی شده و هم اکنون بیش از 100 میلیون کاربر در چین، ژاپن، آمریکا، هند و
اندونزی دارد. مسئله اینه که کاری کنیم تا پاسخ های بات مشابه پاسخ هایی
باشه که رفیق آدمیزادیمون به ما میده! (البته مسئله جدیدی نیست!) پیش رفت
هایی که در حوزه یادگیری عمیق بدست آمده به ما بیشتر کمک می کنه تا بتونیم
به این هدف نزدیک بشیم. نکته ای که لازمه اشاره بشه اینه که داریم در مورد
مکالمه (Converation) صحبت می کنیم نه صرفا پرسش و پاسخ تک مرحله یا چند
مرحله ای.
نوآوری
این مقاله در حقیقت یک مطالعه (Survey) پیرامون پژوهش های انجام شده در زمینه هوش مصنوعی مکالمه است. این مقاله سعی کرده رویکردهای اتخاذ شده در این زمینه را دسته بندی و به طور اجمالی تحلیل نماید. این مقاله بات های مکالمه را به دو دسته خاص منظوره (task-oriented) و عمومی (non-task-oriented) دسته بندی می شود. این مطالعه بررسی پژوهش های انجام شده در زمینه بات های خاص منظوره را کنار گذاشته و تنها به بات های عمومی پرداخته است.
پژوهش های انجام شده سه رویکرد مبتنی بر بازیابی –Retrieval-based– (یافتن بهترین پاسخ به سوال از درون پایگاه داده) و مبتنی بر تولید –Generation-based– (تولید جملات معنی دار) و رویکرد ترکیبی –System Ensemble– از دو روش قبل را اتخاذ کرده اند. بات های تجاری طراحی شده برای دنیای واقعی بیشتر مبتنی بر رویکرد اول طراحی شده اند. یک پایگاه داده بزرگ از جفت (سوال، پاسخ) داریم و بهترین تطبیق رو از اون پیدا می کنیم اما در روش دوم جمله سازی می کنیم.
در میان پژوهش های انجام شده برخی مقالات به این موضوع پرداخته اند که توجه به زمینه ای که در آن گفتگو می کنیم (Context)، نکته کلیدی در مکالمه ها است. در حقیقت اگر بدانیم در چه زمینه ای صحبت می کنیم، قادر خواهیم بود جملات بهتری در پاسخ به طرف مقابل انتخاب کنیم. هدف در درجه اول یافتن مرتبط ترین زمینه به یک مکالمه است. پژوهش هایی هم در زمینه مدلسازی زمینه انجام شده است.
برخی مقالات نیز انتخاب پاسخ مناسب از میان چند پاسخ ممکن به سوال را مورد بررسی قرار داده اند. اساسا یه سوال لزوما یک پاسخ ندارد. این یک ارتباط یک به چند میان سوال و پاسخ ها را نشان می دهد. روش های مختلفی برای انتخاب پاسخ از میان کاندیداها ارائه شده است.
عموما بات های موجود به صورت غیر فعال (Passive) عمل می کنند. به این معنی که منتظر سوال از طرف کاربر انسانی می مانند و به آن پاسخ می دهند. برخی از پژوهش ها رویکردهای فعال را بررسی کرده اند. به این صورت که در شروع مکالمه و یا ایجاد گفتگو جدید بات اقدام به طرح مسئله می کند نه عامل انسانی.
در آخر برخی از مقالات هم در زمینه معیارهای ارزیابی Metrics) خوب بودن یک مکالمه میان ماشین و انسان بررسی شده اند. اساسا ما به ابزاری نیاز داریم تا کیفیت مکالمه را اندازه گیری کند. مقالاتی که در این بخش معرفی شده اند به نسبت قدیمی ترند.
تحلیل
این مقاله مثل همه مطالعه ها (survey) از این جهت که سعی کرده تا کارهای انجام شده تا به حال رو تجمیع کنه خوبه. متاسفانه ظاهرا محدودیت هایی از نظر حجم متوجه این مقاله بوده است. از این رو تحلیل جامعی در مورد مقاله های بررسی شده، انجام نشده است. بیشتر دسته بندی ها مشخص و مقالات هر دسته فهرست شده است. به نظر میرسد به زودی نسخه مجله این مقاله با حجم بیشتر و طبیعتا تحلیل بیشتر ارائه شود.
بررسی دیگران
یه بررسی روی وب پیدا کردم که می تونید اون رو از اینجا مطالعه بفرمایید.
مطالب مرتبط:
مراجع مهم
1. [Li et al., 2016d] Xiang Li, Lili Mou, Rui Yan, and Ming Zhang. Stalematebreaker: A proactive content-introducing approach to automatic human-computer conversation. In IJCAI’16, pages 2845–2851, 2016
2. [Lowe et al., 2017] Ryan Lowe, Michael Noseworthy, Iulian Vlad Serban, Nicolas Angelard-Gontier, Yoshua Bengio, and Joelle Pineau. Towards an automatic turing test: Learning to evaluate dialogue responses. In ACL’17, pages 1116–1126, 2017
3. [Shang et al., 2018] Mingyue Shang, Zhenxin Fu, Nanyun Peng, Yansong Feng, Dongyan Zhao, and Rui Yan. Learning to converse with noisy data: Generation with calibration. In IJCAI’18, 2018
4. [Tao et al., 2018b] Chongyang Tao, Lili Mou, Dongyan Zhao, and Rui Yan. Ruber: An unsupervised method for automatic evaluation of open-domain dialog systems. In AAAI’18, 2018.
دیدگاهتان را بنویسید